
pandas es una biblioteca de Python diseñada para agilizar el proceso de trabajo con datos relacionales. Tiene dos estructuras básicas para capturar y manipular datos: Series y DataFrames.
Cuando se trabaja con estas estructuras de datos, a menudo es necesario filtrar las filas para verificar un subconjunto de los datos o para limpiar el conjunto de datos, por ejemplo, para eliminar los duplicados.
Afortunadamente, Pandas y Python ofrecen múltiples formas de filtrar filas en series y marcos de DataFrames, para que pueda obtener las respuestas que necesita para ejecutar su estrategia comercial. Esta publicación cubrirá los siguientes enfoques:
Cómo filtrar poemas en pandas
1. Cómo filtrar filas por valor de columna
A menudo, desea encontrar instancias de un valor específico en su DataFrame. Puede filtrar filas fácilmente en función de si contienen un valor o no mediante el método de indexación .loc.
En este ejemplo, tiene un DataFrame simple que contiene números enteros aleatorios en dos columnas y 10 filas:
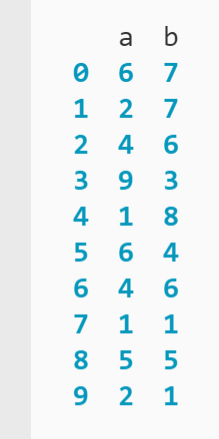
Suponga que desea mostrar solo las filas que tienen un valor 2 en la columna «a». .loc[] le permite definir fácilmente este parámetro:
num_df.loc[num_df['a'] == 2]
Aquí, .loc[] toma una expresión booleana como argumento, lo que significa que cada vez que el valor en la columna «a» z número_df es igual a 2 – expresión devuelve un valor booleano Real – la función devuelve la fila apropiada.
El resultado de ejecutar este código e imprimir el resultado se muestra a continuación.

Como era de esperar, el método .loc revisó cada uno de los valores en la columna «a» y filtró todas las filas que no contienen un número entero 2dejándote con dos líneas que coinciden con tu parámetro.
Para obtener más información sobre el método .loc, consulte nuestra guía sobre indexación en Pandas. Esta guía también analiza el operador de indexación utilizado en el Ejemplo 2 y el método .iloc utilizado en el Ejemplo 3.
2. Cómo filtrar filas según condiciones lógicas
En algunos casos, no querrá buscar filas con un solo valor, sino grupos basados en patrones. Puede definir patrones con expresiones booleanas.
En este escenario, tiene un DataFrame con 10 puntajes de exámenes de estudiantes para la clase. Puedes consultar los datos que contiene a continuación.
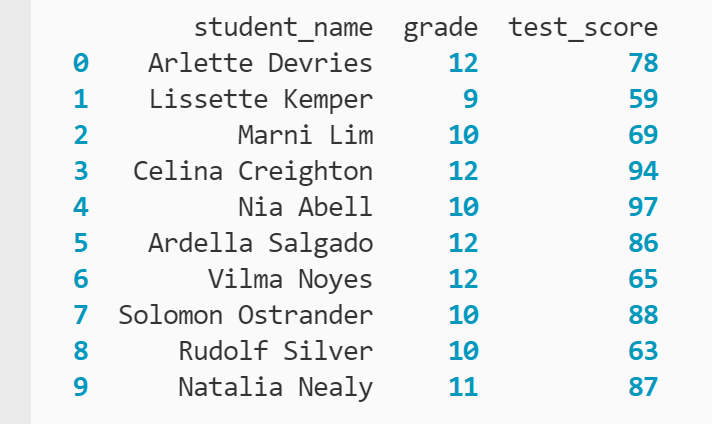
Si solo desea verificar los puntajes de las pruebas de los estudiantes en grados superiores, puede definir la lógica como un argumento para el operador de índice ([]):
tests_df[(tests_df['grade'] > 10)]
Como en el ejemplo anterior, está filtrando pruebas_df DataFrame para mostrar solo filas donde los valores en la columna «Calificación» son mayores que (>) 10. La expresión ejecutada según lo previsto se puede confirmar imprimiendo en el terminal:
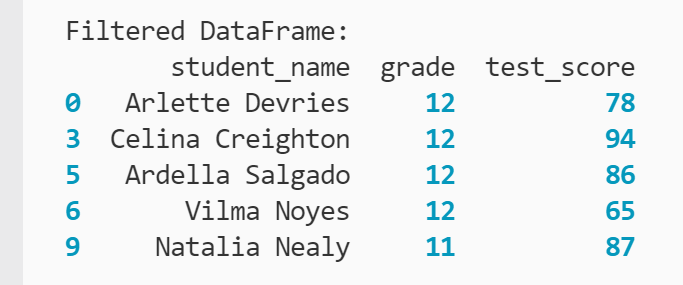
Ahora tiene un subconjunto de cinco líneas para cada uno de sus estudiantes de clase alta. Puede confirmarlo consultando la columna «puntuación». solo valores 11 y 12 están presentes.
Puede agregar condiciones adicionales con el operador lógico & (que representa «y»). Ahora segmenta más los datos para mostrar solo los mejores estudiantes de la clase alta:
tests_df[(tests_df['grade'] > 10) & (tests_df['test_score'] > 80)]
Basado en ciertas condiciones, el estudiante debe estar por encima 10 y obtuvo una puntuación superior a 80 En la prueba. Si una de estas condiciones o ambas son falsas, su fila se filtra.
La salida está debajo.

El subconjunto de datos ahora está más segmentado para mostrar tres filas que satisfacen nuestras dos condiciones.
Puede aumentar la flexibilidad de sus condiciones con un operador lógico | (que representa «o»). En este ejemplo, el código mostrará filas con un nivel de calificación superior a 10 o un resultado de prueba mayor que 80. Solo se necesita cumplir una condición para que se cumpla la expresión:
tests_df[(tests_df['grade'] > 10) | (tests_df['test_score'] > 80)]
En el siguiente ejemplo, exploraremos otra forma de filtrar filas con indexación: el método .iloc.
3. ¿Cómo filtro las filas por sector?
A veces, no desea filtrar en función del valor, sino en función de la posición. El método .iloc le permite definir fácilmente un segmento de DataFrame para recuperar.
Este ejemplo utiliza el conjunto de datos de salarios de Major League Baseball en la fecha Kaggle. Siéntase libre de descargar y seguir.
Puede ver la vista previa de datos a continuación.
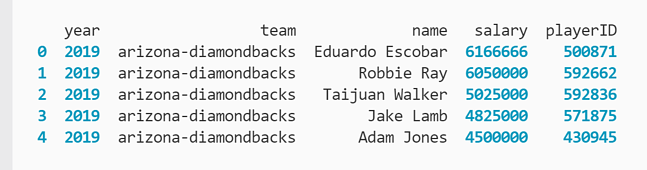
En este escenario, le interesa menos el año en que se recopilaron los datos o el nombre del equipo de cada jugador. Solo necesita una pequeña muestra de las primeras 10 líneas de datos que incluyen el nombre del jugador, el salario y la identificación del jugador.
.iloc le permite definir rápidamente este segmento:
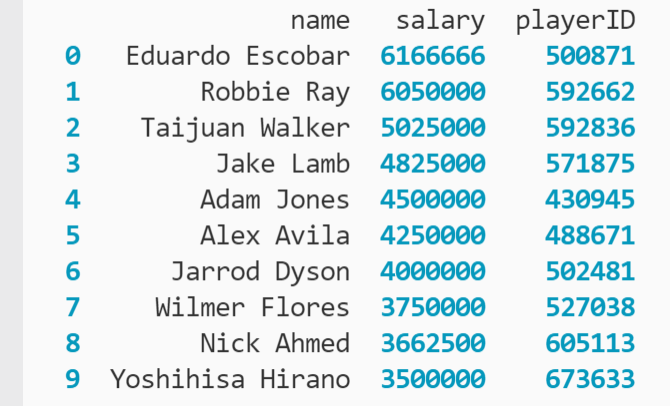
mlb_df.iloc[0:10, 2:5]
Aquí se definen rangos como argumentos para .I loc[] que luego recupera los valores de fila y columna en las ubicaciones especificadas. El primer argumento identifica las líneas que comienzan con el índice 0 y antes del indice 10devolviendo 10 líneas de datos.
El segundo argumento son las columnas que comienzan con el índice. 2 y antes del indice 5, devolviendo tres columnas de datos. La salida está debajo.
Si decide que desea ver un subconjunto de 10 filas y todas las columnas, puede reemplazar el segundo argumento con .I loc[] con dos puntos:
mlb_df.iloc[0:10, :]
Pandas interpretará que los dos puntos significan todas las columnas, como se puede ver en el resultado:
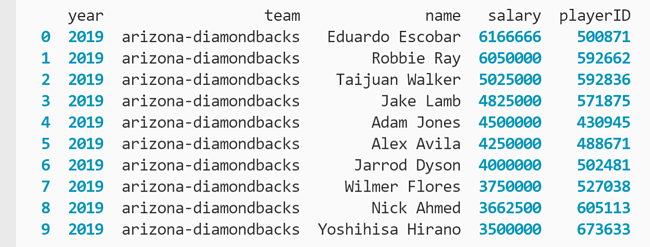
También puede usar dos puntos para seleccionar todas las líneas.
Volvamos al filtrado condicional con el método .query.
4. Cómo filtrar filas por consulta
El método .query pand le permite definir una o más condiciones como una cadena. También elimina la necesidad de utilizar cualquiera de los operadores de indexación ([].loc, .iloc) para acceder a las filas de DataFrame.
En este escenario, nuevamente tiene un DataFrame que consta de dos columnas de números enteros generados aleatoriamente:

Puede definir rápidamente un rango de números como una cadena para que la función .query () se recupere del DataFrame:
num_df.query('a < 8 and a > 3')
Aquí, .consulta() Encontrará cualquier fila donde el valor en la columna «a» sea menor que 8 y mayor que 3. Puede confirmar la ejecución de la función como se esperaba imprimiendo el resultado:
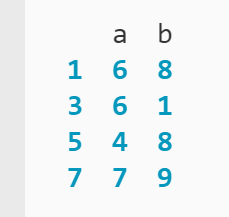
Ha filtrado el DataFrame de 10 filas de datos a cuatro, donde los valores en la columna «a» están entre 4 y 7. Tenga en cuenta que no tuvo que usar la indexación al definir las columnas a las que se debe aplicar cada condición, como en el Ejemplo 2.
Este video de Sean MacKenzie ofrece una demostración en vivo del método .query:
5. Cómo filtrar filas por valores faltantes
No todos los conjuntos de datos están completos. Pandas proporciona una manera fácil de filtrar filas con valores faltantes utilizando el método .notnull.
En este ejemplo, tiene un DataFrame con enteros aleatorios en tres columnas:
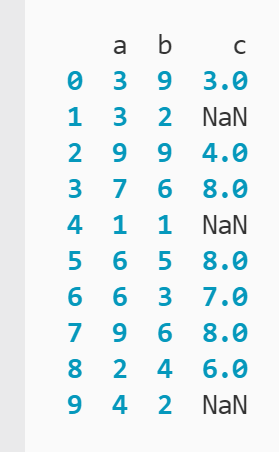
Sin embargo, es posible que haya notado que a la columna «c» le faltan tres valores marcados con NaN (no un número). Puede filtrar estos registros incompletos del DataFrame usando .notnull() y el operador de índice:
num_df[num_df['c'].notnull()]
estas llamando aqui .no es cero () en cada valor contenido en la columna «c». Fiel a su nombre, .no es cero () evalúa si los datos en cada fila son nulos o no. Si los datos no están en blanco, .no es cero () devoluciones Real. Utiliza el segundo operador de índice para luego aplicar la serie lógica generada por .no es cero () como clave para mostrar solo las filas que se evalúan como Real.
El resultado de esta expresión se muestra a continuación.
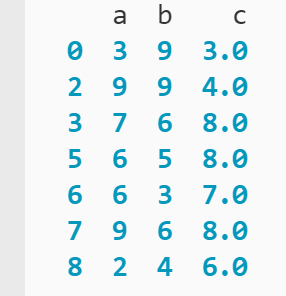
Quitó las tres filas nulas del marco de datos, por lo que su análisis solo incluye registros con datos completos.
El último método parte de las condiciones numéricas para ver cómo filtrar filas que contienen datos de cadena.
6. Cómo filtrar filas usando métodos de cadena
La mayoría de los ejemplos en esta publicación se enfocan en filtrar valores numéricos. Sin embargo, también puede aplicar estos métodos a datos de cadenas. De hecho, las cadenas tienen su propio subconjunto de métodos que le permiten filtrar y segmentar sus datos con una precisión aún mayor.
En este ejemplo, tiene un DataFrame que contiene datos de registro de usuario:

Quiere ver los usuarios que se registraron este año (2022). Dado que las fechas de registro se almacenan como cadenas, puede usar la propiedad .str y el método .contains para buscar ese valor en una columna:
user_df[user_df['sign_up_date'].str.contains('2022')]
Está utilizando el operador de índice nuevamente para buscar en la columna «sign_up_date». Tu usas.pags propiedad para acceder .contiene() método para juzgar si cada cadena en la columna especificada contiene «2022». Aquellas líneas que se evalúan como verdaderas son luego mostradas por el segundo operador de índice.
El resultado está abajo.

Puede reutilizar esta sintaxis para buscar usuarios de la misma ciudad. Como sabe que la ciudad siempre será el primer valor en la columna «ciudad_estado», puede usar el método .startswith para evaluar cadenas:
user_df[user_df['city_state'].str.startswith('Boston')]
Aunque .contains también funcionaría aquí, Empezar con () es más eficiente porque afecta solo al comienzo de la cadena. Tan pronto como encuentre un carácter que no coincida con «Boston» (como «C» en Cambridge en lugar de «B»), la función avanzará al siguiente valor.
Tenga en cuenta que los métodos .contains y .startswith distinguen entre mayúsculas y minúsculas, por lo que buscar «boston» no arrojará ningún resultado.
Este video de sage81564 muestra otro método de cadena que usa .contains y .loc:
Filtra líneas en Pandas para obtener respuestas más rápido.
No todos los datos se crean de la misma manera. El filtrado de filas de Pandas elimina los datos redundantes o no válidos, por lo que obtiene el conjunto de datos más limpio disponible. Puede filtrar por valores, condiciones, sectores, consultas y métodos de cadena. Incluso puede eliminar rápidamente filas con datos faltantes para asegurarse de que solo está trabajando con registros completos. Todos estos enfoques lo ayudarán a encontrar información valiosa para guiar sus operaciones comerciales y definir su estrategia de manera más fácil y rápida.







